Meet Faur Tron
Deploy and optimize GenAI Models in minutes. Enterprise-ready solutions for faster inference, lower costs, and seamless fine-tuning, on-prem or in cloud.
Roll out your AI agent use case – Fast and Performant
Task-Specific Models
Task-Specific Models
Task-Specific Models
Model specialization enables businesses to trade off small to moderate upfront costs for significant long-term savings by allowing the use of smaller, more efficient models tailored to well-defined business use-cases.
Model specialization enables businesses to trade off small to moderate upfront costs for significant long-term savings by allowing the use of smaller, more efficient models tailored to well-defined business use-cases.
Model specialization enables businesses to trade off small to moderate upfront costs for significant long-term savings by allowing the use of smaller, more efficient models tailored to well-defined business use-cases.
Composable Building Blocks
Composable Building Blocks
Composable Building Blocks
Our solutions leverage the unique characteristics of each individual use case and are available as fully managed services or reusable components that can be easily integrated into existing workflows.
Our solutions leverage the unique characteristics of each individual use case and are available as fully managed services or reusable components that can be easily integrated into existing workflows.
Our solutions leverage the unique characteristics of each individual use case and are available as fully managed services or reusable components that can be easily integrated into existing workflows.
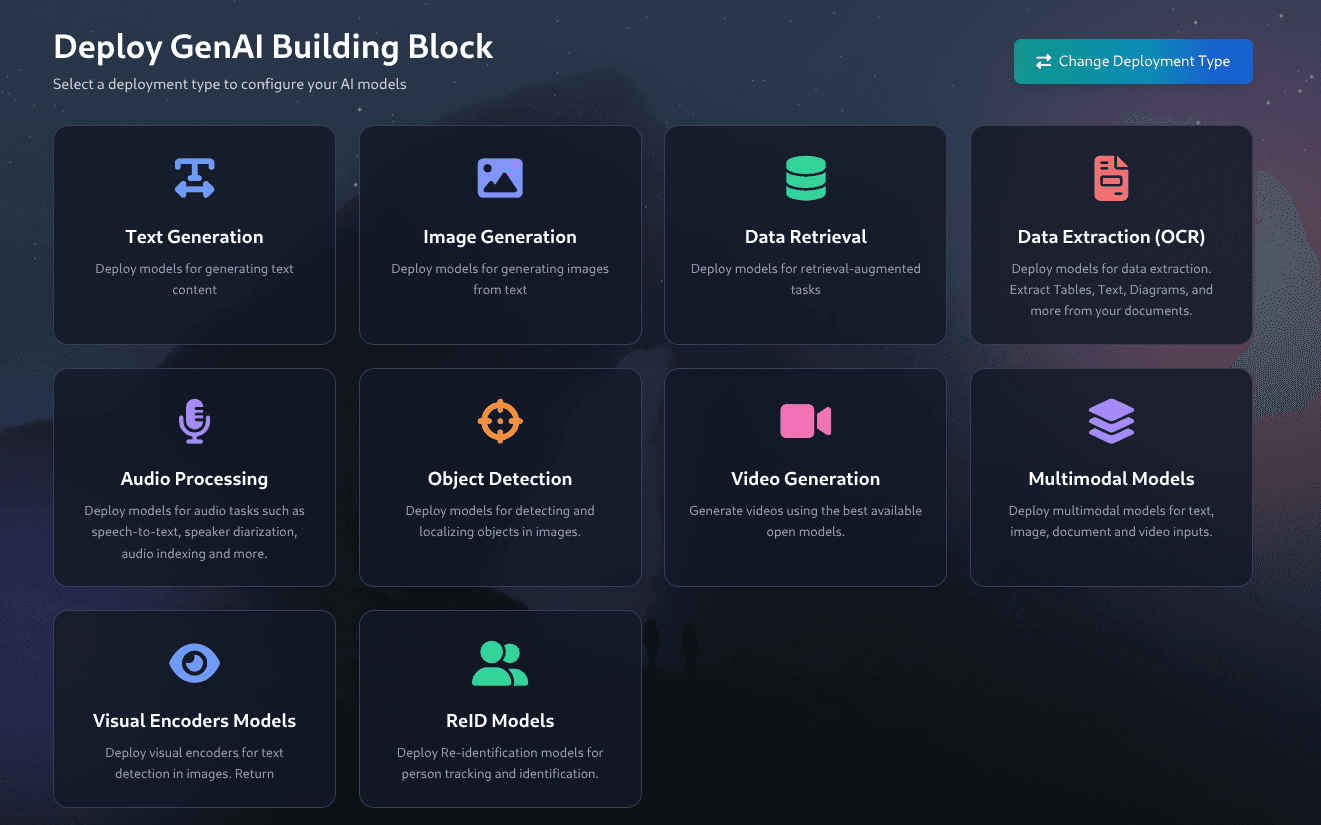
Streamlined Adoption
Streamlined Adoption
Streamlined Adoption
Our platform optimizes every configuration and deployment to reduce costs, while meeting your performance requirements. We offer specialized assistance in optimizing your deployment and integrating into existing business logic.
Our platform optimizes every configuration and deployment to reduce costs, while meeting your performance requirements. We offer specialized assistance in optimizing your deployment and integrating into existing business logic.
Our platform optimizes every configuration and deployment to reduce costs, while meeting your performance requirements. We offer specialized assistance in optimizing your deployment and integrating into existing business logic.
Visual Deployments
Visual Deployments
Visual Deployments
Block style deployments for easy composability of models.
Block style deployments for easy composability of models.
Block style deployments for easy composability of models.
